This page was generated from docs/source/examples/MovieLens100k.ipynb.
Building a Neural Movie Recommender System¶
Despite its name (and the original purpose), timeserio is a general-purpose tool for rapid model development. In this example, we use it to train a state-of-the-art movie recommender system in a few lines of code.
Dataset¶
The MovieLens dataset is commonly used to benchmark recommender systems - see https://grouplens.org/datasets/movielens/100k/.
Our task is to learn to predict how user \(u\) would rate a movie \(m\) (\(r_{um}\)) based on an available dataset of ratings \(r_{ij}\). Importantly, each user has only given ratings to some of the movies, and each movie has only been rated by some of the users. This is a classic example of transfer learning, commonly known as collaborative filtering in the context of recommender systems.
Introduction¶
We make use of keras to define three models: - a user embedder that learns to represent each user’s preference as a vector - a movie embedder that learns to represent each movie as a vector - a rating model that concatenates user and movie embedding networks, and applies a dense neural network to predict a (non-negative) rating
By wrapping the three models in a multinetwork (of the MultiNetworkBase class), we can for example - train the rating model end-to-end, then use one of the embedding models - freeze one or both of the embedding models and re-train the dense layers, or - freeze the dense layers, and re-train embeddings for new users only
To make our job even simpler, we further wrap our multinetwork in a MultiModel class, which allows us to take data directly from pandas DataFrames, and apply pre-processing pipelines if needed.
[73]:
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt
import seaborn as sns
plt.xkcd();
Download data¶
First, we download the freely available dataset and define a few helper functions for importing data.
[21]:
!mkdir -p datasets; cd datasets; wget http://files.grouplens.org/datasets/movielens/ml-100k.zip; unzip -o ml-100k.zip; rm ml-100k.zip
--2019-06-22 14:53:38-- http://files.grouplens.org/datasets/movielens/ml-100k.zip
Resolving files.grouplens.org (files.grouplens.org)... 128.101.65.152
Connecting to files.grouplens.org (files.grouplens.org)|128.101.65.152|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 4924029 (4.7M) [application/zip]
Saving to: ‘ml-100k.zip’
ml-100k.zip 100%[===================>] 4.70M 2.00MB/s in 2.3s
2019-06-22 14:53:41 (2.00 MB/s) - ‘ml-100k.zip’ saved [4924029/4924029]
Archive: ml-100k.zip
inflating: ml-100k/allbut.pl
inflating: ml-100k/mku.sh
inflating: ml-100k/README
inflating: ml-100k/u.data
inflating: ml-100k/u.genre
inflating: ml-100k/u.info
inflating: ml-100k/u.item
inflating: ml-100k/u.occupation
inflating: ml-100k/u.user
inflating: ml-100k/u1.base
inflating: ml-100k/u1.test
inflating: ml-100k/u2.base
inflating: ml-100k/u2.test
inflating: ml-100k/u3.base
inflating: ml-100k/u3.test
inflating: ml-100k/u4.base
inflating: ml-100k/u4.test
inflating: ml-100k/u5.base
inflating: ml-100k/u5.test
inflating: ml-100k/ua.base
inflating: ml-100k/ua.test
inflating: ml-100k/ub.base
inflating: ml-100k/ub.test
[22]:
def get_ratings(part='u.data'):
"""Return a DataFrame of user-movie ratings."""
return pd.read_csv(
os.path.join('datasets/ml-100k', part), header=None, sep='\t',
names=['user_id', 'item_id', 'rating', 'timestamp'],
).rename(columns={'item_id': 'movie_id'})
def get_users():
"""Return a DataFrame of all users."""
return pd.read_csv(
os.path.join('datasets/ml-100k', 'u.user'), header=None, sep='|',
names=['user_id', 'age', 'gender', 'occupation', 'zip_code'],
).rename(columns={'item_id': 'movie_id'})
ITEM_PROPS = ['movie_id', 'movie_title', 'video_release_date', 'unknown', 'IMDb_URL']
GENRES = ['Action', 'Adventure', 'Animation',
'Childrens', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy',
'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi',
'Thriller', 'War', 'Western']
def get_movies():
"""Return a DataFrame of all movies."""
return pd.read_csv(
os.path.join('datasets/ml-100k', 'u.item'), header=None, index_col=False, sep='|', encoding="iso-8859-1",
names=ITEM_PROPS + GENRES,
)
[23]:
get_ratings().head(3)
[23]:
| user_id | movie_id | rating | timestamp | |
|---|---|---|---|---|
| 0 | 196 | 242 | 3 | 881250949 |
| 1 | 186 | 302 | 3 | 891717742 |
| 2 | 22 | 377 | 1 | 878887116 |
[24]:
get_users().head(3)
[24]:
| user_id | age | gender | occupation | zip_code | |
|---|---|---|---|---|---|
| 0 | 1 | 24 | M | technician | 85711 |
| 1 | 2 | 53 | F | other | 94043 |
| 2 | 3 | 23 | M | writer | 32067 |
[25]:
get_movies().head(3)
[25]:
| movie_id | movie_title | video_release_date | unknown | IMDb_URL | Action | Adventure | Animation | Childrens | Comedy | ... | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | Thriller | War | Western | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?Toy%20Story%2... | 0 | 0 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | GoldenEye (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?GoldenEye%20(... | 0 | 1 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 3 | Four Rooms (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?Four%20Rooms%... | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
3 rows × 23 columns
Define the model architecture¶
We start by defining the network architecture. All we need to do is sub-class MultiNetworkBase, and define the _model method.
keyword arguments to
_modelare used to parametrise our network architecture, e.g. by specifying a settable number of neurons or layersthe
_modelmethod is expected to return a dictionary ofkeras.models.Modelobjects.
[26]:
from keras.layers import Input, Embedding, Dense, Concatenate, Flatten
from keras.models import Model
Using TensorFlow backend.
[36]:
from timeserio.keras.multinetwork import MultiNetworkBase
class MovieLensNetwork(MultiNetworkBase):
def _model(self,
user_dim=2, item_dim=2, max_user=10000, max_item=10000,
hidden=8):
user_input = Input(shape=(1,), name='user')
item_input = Input(shape=(1,), name='movie')
user_emb = Flatten(name='flatten_user')(Embedding(max_user, user_dim, name='embed_user')(user_input))
item_emb = Flatten(name='flatten_movie')(Embedding(max_item, item_dim, name='embed_movie')(item_input))
output = Concatenate(name='concatenate')([user_emb, item_emb])
output = Dense(hidden, activation='relu', name='dense')(output)
output = Dense(1, name='rating')(output)
user_model = Model(user_input, user_emb)
item_model = Model(item_input, item_emb)
rating_model = Model([user_input, item_input], output)
rating_model.compile(optimizer='Adam', loss='mse', metrics=['mae'])
return {'user': user_model, 'movie': item_model, 'rating': rating_model}
The three models are initialized on-demand, e.g. when we access multinetwork.model. Note that the inputs and embedding layers are shared, and therefore changes made to e.g. the user model are instantly available in the rating model.
[44]:
multinetwork = MovieLensNetwork()
multinetwork.model
[44]:
{'user': <keras.engine.training.Model at 0x139c6c438>,
'movie': <keras.engine.training.Model at 0x139c8eac8>,
'rating': <keras.engine.training.Model at 0x139c8e5c0>}
[45]:
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils.layer_utils import print_summary
[46]:
SVG(model_to_dot(multinetwork.model['user'], rankdir='LR').create(prog='dot', format='svg'))
[46]:

[47]:
SVG(model_to_dot(multinetwork.model['movie'], rankdir='LR').create(prog='dot', format='svg'))
[47]:

[48]:
SVG(model_to_dot(multinetwork.model['rating']).create(prog='dot', format='svg'))
[48]:

[49]:
print_summary(multinetwork.model['rating'])
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
user (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
movie (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
embed_user (Embedding) (None, 1, 2) 20000 user[0][0]
__________________________________________________________________________________________________
embed_movie (Embedding) (None, 1, 2) 20000 movie[0][0]
__________________________________________________________________________________________________
flatten_user (Flatten) (None, 2) 0 embed_user[0][0]
__________________________________________________________________________________________________
flatten_movie (Flatten) (None, 2) 0 embed_movie[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 4) 0 flatten_user[0][0]
flatten_movie[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 8) 40 concatenate[0][0]
__________________________________________________________________________________________________
rating (Dense) (None, 1) 9 dense[0][0]
==================================================================================================
Total params: 40,049
Trainable params: 40,049
Non-trainable params: 0
__________________________________________________________________________________________________
From Multinetwork to Multimodel¶
We can train a specific model by using its name. Note that we must provide numpy feature arrays to each input, and also an array of training labels:
multinetwork.fit([X_user, X_movie], y_rating, model='rating')
In our case, we could simply write X_user = df["user_id"].values etc.
However, we prefer different models to be fed from one data source, typically a pandas.DataFrame, with any details of feature pre-processing, or input ordering, taken care of by encapsulated pipelines, providing an interface of the form
multimodel.fit(df, model='rating')
Let’s work through the necessary steps - these may seem trivial for a simple problem, but save a lot of headaches when developing and deploying complex models.
Define individual pipelines¶
We start by defining a pipeline (a scikit-learn transformer) for each of the model inputs and labels:
[52]:
from timeserio.preprocessing import PandasValueSelector
user_pipe = PandasValueSelector('user_id')
item_pipe = PandasValueSelector('movie_id')
rating_pipe = PandasValueSelector('rating')
Group the pipelines in a MultiPipeline¶
The MultiPipeline object provides a container for all the pipelines, with convenience features such as easy parameter accesss. All we need is to provide a name for each pipeline:
[53]:
from timeserio.pipeline import MultiPipeline
multipipeline = MultiPipeline({
'user_pipe': user_pipe,
'movie_pipe': item_pipe,
'rating_pipe': rating_pipe,
})
Connect pipelines to models¶
To finish the plumbing exercise, we specify which pipeline connects to each input or output of each model using a manifold.
Each key-value in the manifold has the form model_name: (input_pipes, output_pipes), where input_pipes is either a single pipe name, or a list of pipe names (one per input). Similarly, the output_pipe will have one ore more pipe names, one per output of the model - we use None for models that we do not intend to train using supervised labels.
[54]:
manifold = {
'user': ('user_pipe', None),
'movie': ('movie_pipe', None),
'rating': (['user_pipe', 'movie_pipe'], 'rating_pipe')
}
Put it all together¶
The MultiModel holds all three parts: - the multinetwork specifies the model architectures, and also training parameters and callbacks - the multipipeline specifies the feature processing pipelines - the manifold specifies which pipelines is plumbed to which input (or output) of which neural network model
[56]:
from timeserio.multimodel import MultiModel
multimodel = MultiModel(
multinetwork=multinetwork,
multipipeline=multipipeline,
manifold=manifold
)
Fit the MultiModel¶
We load one train-test split, and fitting our neural recommender system
[67]:
df_train = get_ratings('u1.base')
df_val = get_ratings('u1.test')
len(df_train), len(df_val)
[67]:
(80000, 20000)
[58]:
from kerashistoryplot.callbacks import PlotHistory
[68]:
# Note: `PlotHistory` callback is rather slow
multimodel.fit(
reset_weights=True,
df=df_train, model='rating', validation_data=df_val,
batch_size=4096, epochs=50,
callbacks=[PlotHistory(batches=True, n_cols=2, figsize=(15, 8))]
)

[68]:
<timeserio.keras.callbacks.HistoryLogger at 0x13d5189e8>
The multimodel provides all the familiar methods such as fit, predict, or evaluate:
[70]:
mse, mae = multimodel.evaluate(df_val, model="rating")
print(f"MSE: {mse}, RMSE: {np.sqrt(mse)}, MAE: {mae}")
MSE: 0.9139011481761933, RMSE: 0.9559817718849002, MAE: 0.7554579020500183
Cross-Validate our approach¶
To evaluate how well recommender system performs, we perform 5-fold cross-validation and compare scores established benchmarks.
[71]:
from sklearn.metrics import mean_absolute_error, mean_squared_error
[74]:
%%time
folds = [1, 2, 3, 4, 5]
folds_mse = []
folds_rmse = []
folds_mae = []
for fold in tqdm(folds, total=len(folds)):
multimodel.multinetwork._init_model()
df_train = get_ratings(f'u{fold}.base')
df_val = get_ratings(f'u{fold}.test')
multimodel.fit(
df=df_train, model='rating', validation_data=df_val,
batch_size=4096, epochs=50, verbose=0,
reset_weights=True
)
y_pred = multimodel.predict(df=df_val, model='rating')
mse = mean_squared_error(df_val['rating'], y_pred)
mae = mean_absolute_error(df_val['rating'], y_pred)
folds_mse.append(mse)
folds_rmse.append(np.sqrt(mse))
folds_mae.append(mae)
100%|██████████| 5/5 [01:00<00:00, 12.28s/it]
CPU times: user 1min 6s, sys: 4.14 s, total: 1min 10s
Wall time: 1min
[75]:
print(
f"5-fold Cross-Validation results: \n"
f"RMSE: {np.mean(folds_rmse):.2f} ± {np.std(folds_rmse):.2f} \n"
f"MAE: {np.mean(folds_mae):.2f} ± {np.std(folds_mae):.2f} \n"
)
5-fold Cross-Validation results:
RMSE: 0.94 ± 0.01
MAE: 0.74 ± 0.00
Benchmarks for some modern algorithms can be seen e.g. at http://surpriselib.com/ or https://www.librec.net/release/v1.3/example.html - our approach is in fact competitive with the state of the art before any tuning! By using dense embeddings, we did not use any user features such as gender or age - all we need is to learn their preference embedding as part of our end-to-end model.
We are now free to experiment with embedding dimensions for users and movies, or tweak the dense layers.
Using multiple models¶
We now use a trained MultiModel to inspect the embeddings. Because we defined user and movie embedders as independent models, we can simple call .predict(..., model=...) with different model names.
User embeddings¶
[76]:
user_df = get_users()
[77]:
embeddings = multimodel.predict(user_df, model='user')
user_df['emb_0'] = embeddings[:, 0]
user_df['emb_1'] = embeddings[:, 1]
[78]:
sns.scatterplot(x='emb_0', y='emb_1', hue='gender', size='age', data=user_df)
[78]:
<matplotlib.axes._subplots.AxesSubplot at 0x143dac320>
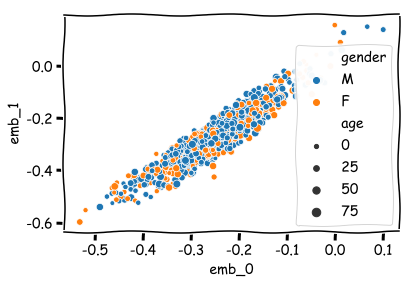
And the movie embeddings…¶
[79]:
movie_df = get_movies()
[81]:
embeddings = multimodel.predict(movie_df, model='movie')
movie_df['emb_0'] = embeddings[:, 0]
movie_df['emb_1'] = embeddings[:, 1]
Out of curiosity, we can compute mean embeddings for movies tagged with each genre.
[85]:
genre_df = pd.DataFrame()
for genre in GENRES:
mean = movie_df[movie_df[genre] == 1][['emb_0', 'emb_1']].mean()
mean['genre'] = genre
genre_df = genre_df.append(mean, ignore_index=True)
Movie and Genre embeddings¶
[88]:
fig, axes = plt.subplots(ncols=2, figsize=(20, 8))
sns.scatterplot(x='emb_0', y='emb_1', data=movie_df, ax=axes[0], palette='bright')
sns.scatterplot(x='emb_0', y='emb_1', hue='genre', data=genre_df, ax=axes[1], palette='bright')
[88]:
<matplotlib.axes._subplots.AxesSubplot at 0x1443e4f98>
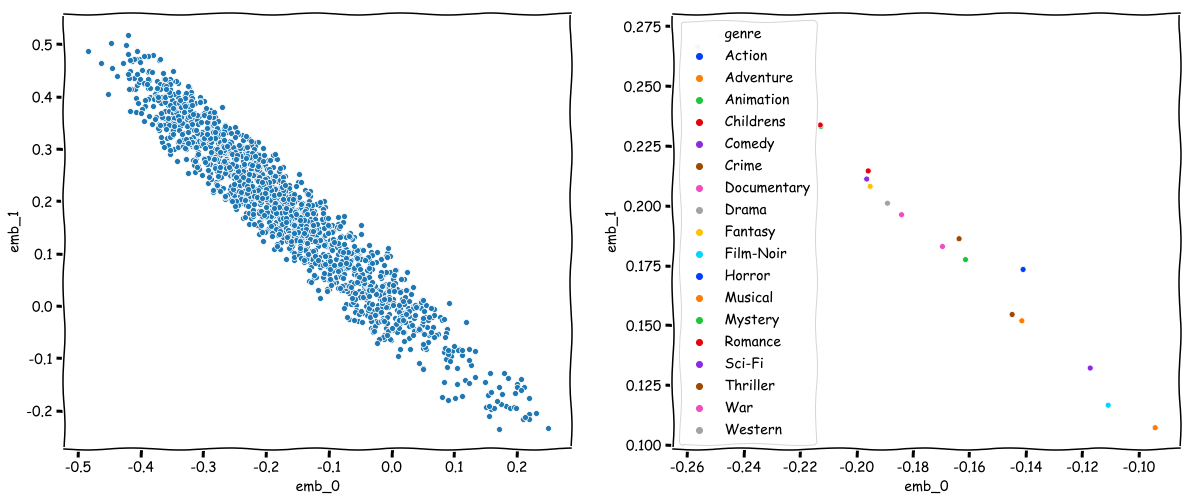
We can even consider similarity between genres by: - computing centroid for each genre - performing hierarchical clustering on genre centroids - plotting the distance matrix with a fancy colour scheme
[89]:
from sklearn.metrics import pairwise_distances
from scipy.cluster import hierarchy
[90]:
X = genre_df[['emb_0', 'emb_1']].values
Z = hierarchy.linkage(X)
order = hierarchy.leaves_list(hierarchy.optimal_leaf_ordering(Z, X))
genre_df_ordered = genre_df.iloc[order]
[91]:
embs_ord = genre_df_ordered[['emb_0', 'emb_1']].values
dist_ord = pairwise_distances(embs_ord)
genres_ord = genre_df_ordered['genre'].values
[92]:
sns.heatmap(dist_ord, xticklabels=genres_ord, yticklabels=genres_ord, cmap='plasma_r');
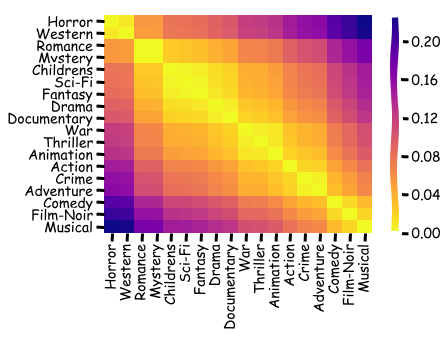
We see that the two genres furthest apart are Horror and Musical, while Romance and Mystery or Crime and Adventure evoke similar rating patterns!
Freezing and partial updating¶
Finally, we mention another key advantage of the MultiModel approach: partial re-training.
Imagine we have a powerful production system, but new users register with our service every day.
We don’t want to re-train the full model, only the embeddings for new users. This is trivial:
multimodel.fit(
trainable_models=['user'],
df=df_new, model='rating', **kwargs
)
This will ensure that only the user embeddings are updated (and only for users present in df_new, while dense layer weights and movie embeddings remain frozen.